 Malcolm Slaney
Malcolm Slaney
Dr. Malcolm Slaney
is a Consulting Professor
at Stanford CCRMA,
where he has led the Hearing Seminar for more than 20 years,
and an
Affiliate Faculty
in the Electrical Engineering Department at the University of Washington.
He is a coauthor, with A. C. Kak, of the IEEE book "Principles of Computerized Tomographic Imaging."
This book was republished by SIAM in their
"Classics in Applied Mathematics" Series.
He is coeditor, with Steven Greenberg, of the book
"Computational Models of Auditory Function."
Dr. Slaney has a long career in industry, including doing machine learning and auditory perception work at
Google Research.
Before Google, Dr. Slaney worked at Bell Laboratory, Schlumberger Palo Alto Research, Apple Computer,
Interval Research, IBM's Almaden Research Center, Yahoo! Research, and Microsoft Research.
For many years, he has led the auditory group at the
Telluride Neuromorphic Cognition Engineering Workshop.
Dr. Slaney's recent work is on understanding the role of attention in conversational speech and general audio perception.
Awards:
Publications and Pointers
A more complete list of my publications is at this link:
Publications by Year or on
Google Scholar.
I used to work in the Machine Hearing group, which is part of the
Machine Perception group, at Google Research in Mountain View, CA.
Before that I was in the Speech
and Dialog group at Microsoft Research in Mountain View, CA,
Yahoo!
Research and IBM's Almaden
Research Center. My IBM work is described on this page.
Before that I worked for Interval
Research, Apple Computer's Advanced Technology Group, and
Schlumberger Palo Alto Research.
Several of my technical reports and papers are available on the
net for downloading. The following is a brief list. I have a personal web page for
the fun stuff. Many of my papers can be found online via the IEEE
or the ACM
portals.
This page shows my
auditory perception,
machine learning,
multimedia analysis work,
auditory modeling work,
my signal processing work,
some of my software tools,
and pointers to other work.
Note! My tomography
book is now online. Get more information here. The book
is back in print and you can order it now from SIAM. SIAM
honored us by including it in their "Classics
in Applied Mathematics"series of books!!!
Auditory Perception
Machine Learning
Multimedia Analysis
 I spent a few years investigating an algorithm
known as Locality Sensitive Hashing (LSH) that is used to
efficiently find nearest neighbors. I wanted to understand
how to make LSH more efficient. I wrote a tutorial
with Michael Casey and Christoph Rhodes. Then with
colleagues at Yahoo I wrote a "definitive" article about how
to choose the optimum parameters. Both the Matlab
(optimization) and Python (implementation) code is online
too. I spent a few years investigating an algorithm
known as Locality Sensitive Hashing (LSH) that is used to
efficiently find nearest neighbors. I wanted to understand
how to make LSH more efficient. I wrote a tutorial
with Michael Casey and Christoph Rhodes. Then with
colleagues at Yahoo I wrote a "definitive" article about how
to choose the optimum parameters. Both the Matlab
(optimization) and Python (implementation) code is online
too.
|
A tutorial
about LSH.
How to optimize
LSH
GIT
Repository for Matlab and Python Code
|
 I wrote a column for IEEE Multimedia
Magazine about my vision of the multimedia world. The
columns are online. I wrote a column for IEEE Multimedia
Magazine about my vision of the multimedia world. The
columns are online. |
Vision and
Views |
 I get to
work with lots of wonderful image data and some very smart
computer-vision people. I get to
work with lots of wonderful image data and some very smart
computer-vision people.
For a couple of years, I worked with Rainer
Lienhart and Eva Hoerster on image classification in large
databases.
|
With Eva and Rainer: CIVR2008,
DAGM2008,
CIVR2007,
ICASSP2007
With Srinivasan: Bipartitate
Models
|
 I've been working on finding similar
songs in large music databases with Michael Casey
at Dartmouth and Goldsmiths College, University of
London. We want to find matches that are similar, but
not exact (fingerprinting finds exact matches.)
Michael wrote a great overview of music-information
retrieval, and I helped edit a special
issue
of IEEE Transactions on Audio, Speech and Language
Processing. I've been working on finding similar
songs in large music databases with Michael Casey
at Dartmouth and Goldsmiths College, University of
London. We want to find matches that are similar, but
not exact (fingerprinting finds exact matches.)
Michael wrote a great overview of music-information
retrieval, and I helped edit a special
issue
of IEEE Transactions on Audio, Speech and Language
Processing.
I've also been working with William
White from Yahoo's media group to better understand
how to deliver music. We've characterized the diversity
of people's musical interests, studied item-to-item
similarity (using 480,000 subjects), and, most
recently, survey several techniques for content-based
similarity.
And work with Benjamin Marlin when he was an intern at
Yahoo! Research turned into a nice paper about modeling
uncertainty in rating data.
|
Best overview of our music-similarity work is
in IEEE
TASLP. See earlier work at ICASSP
2007, ICASSP
2006 and ISMIR
2006.
2006 - Music
Diversity
2007 - Item
Similarity
2008 - Content
Similarity
|
Auditory Modeling
 There is now a new version of
the Auditory Toolbox. It contains Matlab functions to
implement many different kinds of auditory models. The
toolbox includes code for Lyon's passive longwave model,
Patterson's gammatone filterbank, Meddis' hair cell model,
Seneff's auditory model, correlograms and several common
representations from the speech-recognition world
(including MFCC, LPC and spectrograms). This code has been
tested on Macintosh, Windows, and Unix machines using
Matlab 5.2. There is now a new version of
the Auditory Toolbox. It contains Matlab functions to
implement many different kinds of auditory models. The
toolbox includes code for Lyon's passive longwave model,
Patterson's gammatone filterbank, Meddis' hair cell model,
Seneff's auditory model, correlograms and several common
representations from the speech-recognition world
(including MFCC, LPC and spectrograms). This code has been
tested on Macintosh, Windows, and Unix machines using
Matlab 5.2.
Note: This toolbox was originally published as Apple
Computer Technical Report #45. The old technical report
( PDF
PDF and Postscript
) and old code ( Unix
TAR and Macintosh
BinHex ) are available for historical reasons.
|
Auditory
Toolbox
(Version
2.0) |
 My primary scientific goal is to
understand how our brains perceive sound. My role in this
research area is a modeler, I build models that explain the
neurophysiological and psychoacoustic data. Hopefully these
models will help other researchers understand the mechanisms
involved and result in better experiments. My latest work in
this area is titled "Connecting Correlograms to
Neurophysiology and Psychoacoustics" and was presented at
the XIth
International
Symposium on Hearing in Grantham England from 1-6
August, 1997. Two correlograms, one computed using
autocorrelation and other other computed using AIM, are
shown on the left. My primary scientific goal is to
understand how our brains perceive sound. My role in this
research area is a modeler, I build models that explain the
neurophysiological and psychoacoustic data. Hopefully these
models will help other researchers understand the mechanisms
involved and result in better experiments. My latest work in
this area is titled "Connecting Correlograms to
Neurophysiology and Psychoacoustics" and was presented at
the XIth
International
Symposium on Hearing in Grantham England from 1-6
August, 1997. Two correlograms, one computed using
autocorrelation and other other computed using AIM, are
shown on the left. |
Abstract |
 I have written
several papers describing how to convert auditory
representations into sounds. I have built models of the
cochlea and central auditory processing, which I hope both
explain auditory processing and will allow us to build
auditory sound separation tools. These papers describe the
process of converting sounds into cochleagrams and
correlograms, and then converting these representations
back into sounds. Unlike the printed versions of this
work, the web page includes audio file examples. It
includes better spectrogram inversion techniques, a
description of how to invert Lyon's passive cochlear
model, and a description of correlogram inversion. This
material was first presented as part of the Proceedings
of the ATR Workshop on "A Biological Framework for
Speech Perception and Production" published in
September 1994. A more refined version of this paper was
an invited talk at the 1994
NIPS
conference. The image on the left shows the
spectrogram of one channel of cochlear output; one step in
the correlogram inversion process. I have written
several papers describing how to convert auditory
representations into sounds. I have built models of the
cochlea and central auditory processing, which I hope both
explain auditory processing and will allow us to build
auditory sound separation tools. These papers describe the
process of converting sounds into cochleagrams and
correlograms, and then converting these representations
back into sounds. Unlike the printed versions of this
work, the web page includes audio file examples. It
includes better spectrogram inversion techniques, a
description of how to invert Lyon's passive cochlear
model, and a description of correlogram inversion. This
material was first presented as part of the Proceedings
of the ATR Workshop on "A Biological Framework for
Speech Perception and Production" published in
September 1994. A more refined version of this paper was
an invited talk at the 1994
NIPS
conference. The image on the left shows the
spectrogram of one channel of cochlear output; one step in
the correlogram inversion process. |
ATR
(Kyoto)
Workshop Web Reprint with Sound Examples
Keynote
NIPS
Conference Paper (Postscript)
|
 Pattern Playback is
the term used by Frank Cooper to describe his successful
efforts to paint spectrogram on plastic and then convert
them into sound. I wrote of Pattern Playback techniques,
from Frank Cooper's efforts to my own efforts with
auditory model inversion, in a paper which was published
at the 1995 IEEE International Conference on Systems,
Man, and Cybernetics. My paper is titled "Pattern
Playback from 1950 to 1995". The image at the left shows a
portion of one of Cooper's spectrograms. Pattern Playback is
the term used by Frank Cooper to describe his successful
efforts to paint spectrogram on plastic and then convert
them into sound. I wrote of Pattern Playback techniques,
from Frank Cooper's efforts to my own efforts with
auditory model inversion, in a paper which was published
at the 1995 IEEE International Conference on Systems,
Man, and Cybernetics. My paper is titled "Pattern
Playback from 1950 to 1995". The image at the left shows a
portion of one of Cooper's spectrograms. |
Web
Version
Postscript
(1.8M)
Adobe
PDF
(227k)
|
The following
are publications during my time at Apple. The Mathematica notebooks
are
designed to be self-documenting and in each case the postscript and
PDF files are also available. Those files that are Matlab toolboxes
include
source and documentation All these files are available with the
gracious permission of Apple.
| "Auditory Model Inversion for Sound
Separation" is the first paper to describe correlogram
inversion techniques. We also discuss improved methods for
inverting spectrograms and a cochlear model designed by
Richard F. Lyon. This paper was published at ICASSP '94. |
Postscript
(1.5M)
Adobe
PDF
(243k)
Online
patent
|
| "A Perceptual Pitch Detector" is a paper
that describes a model of human pitch perception. It is
similar to work done by Meddis and Hewitt and published in
JASA, but this paper has more real-world examples. This
paper was published at ICASSP '90. |
Postscript
(3M)
Adobe
PDF
(315k)
|
| "On the importance of time" is an invited
chapter by Dick Lyon and myself in the book Visual
Representations
of Speech Signals (edited by Martin Cooke,
Steve Beet and Malcolm Crawford, John Wiley & Sons).
This tutorial describes the reason that we think
time-domain processing is important when modeling the
cochlea and higher-level processing. |
Postscript
Adobe
PDF
|
| A software package called MacEar implements
the latest version of Lyon's Cochlear Model. MacEar is
written in very portable C for Unix and Macintosh
computers. This link points to the last published version
(2.2). (Note the README file included has old program
results. The names of the output files have changed and
there are a couple of extra channels being output. I'm
sorry for the confusion.) |
Unix
Shell Archive with Sources |
Signal Processing
| I recently finished some nice work
establishing a linear operator connecting the audio and
video of a speaker. A paper describing this work has been
accepted for presentation at the NIPS'2000 conference. |
PDF
Paper
(600k) |
 Chris Bregler, Michele Covell,
and I developed a technique we call Video Rewrite to
automatically synthesize video of talking heads. This
technology is cool because we use a purely data driven
approach (concatenative triphone video synthesis) to
create new video of a person speaking. Given new audio, we
concatenate the best sequence of lip images and morph them
into a background sequence. We can automatically create
sequences like the Kennedy and Johnson scenes in the movie
"Forrest Gump." Chris Bregler, Michele Covell,
and I developed a technique we call Video Rewrite to
automatically synthesize video of talking heads. This
technology is cool because we use a purely data driven
approach (concatenative triphone video synthesis) to
create new video of a person speaking. Given new audio, we
concatenate the best sequence of lip images and morph them
into a background sequence. We can automatically create
sequences like the Kennedy and Johnson scenes in the movie
"Forrest Gump." |
Original
SIGGRAPH
'97 Paper (with examples)
Audio
Visual
Speech Perception Workshop
|
 We studied how adults convey
affective messages to infants using prosody. We did not
attempt to recognize the words, let alone to distill more
nebulous concepts such as satire or irony. We analyzed
speech with low-level acoustic features and discriminated
approval, attentional bids, and prohibitions from adults
speaking to their infants. We built automatic classifiers
to create a system, Baby Ears, that performs the task that
comes so naturally to infants. The image on the left shows
one of the decision surfaces which classifies approval,
attention and prohibition utterances on the basis of their
pitch. We studied how adults convey
affective messages to infants using prosody. We did not
attempt to recognize the words, let alone to distill more
nebulous concepts such as satire or irony. We analyzed
speech with low-level acoustic features and discriminated
approval, attentional bids, and prohibitions from adults
speaking to their infants. We built automatic classifiers
to create a system, Baby Ears, that performs the task that
comes so naturally to infants. The image on the left shows
one of the decision surfaces which classifies approval,
attention and prohibition utterances on the basis of their
pitch. |
Web
Page
Postscript
(189k)
Adobe
PDF
(42k)
|
| We wrote a more detailed article describing
this work for the journal Speech
Communications. We can't post that article,
but I can send you a copy if you send me email. |
Send email
for a copy of journal article. |
| I was able to help Michele Covell do some
neat work on time-compression of audio. Lots of people
know how to compress a speech utterance by a constant
amount. But if you want to do better, which parts of the
speech signal can be compressed the most? This paper
describes a good technique and shows how to test the
resulting comprehension. |
Conference
Paper
Technical
Report
with Audio Samples
|
 Eric Scheirer and I worked on a
system for discriminating between speech and music in an
audio signal. This paper describes a large number of
features, how they can be combined into a statistical
framework, and the resulting performance on discriminating
signals found on radio stations. The results are better
then anybody else's results. (That comparison is not
necessarily valid since there are no common testing
databases. We did work hard to make our test set
representative.) This paper was published at the 1997
ICASSP in Munich. The image on the left shows clouds of
our data. Eric Scheirer and I worked on a
system for discriminating between speech and music in an
audio signal. This paper describes a large number of
features, how they can be combined into a statistical
framework, and the resulting performance on discriminating
signals found on radio stations. The results are better
then anybody else's results. (That comparison is not
necessarily valid since there are no common testing
databases. We did work hard to make our test set
representative.) This paper was published at the 1997
ICASSP in Munich. The image on the left shows clouds of
our data. |
Web
Page
Postscript
(349k)
Adobe
PDF
(263k)
|
 Work we've done to morph between
two sounds is described in a paper at the 1996 ICASSP.
This work is new because it extends previous audio
morphing work to include inharmonic sounds. This paper
uses results from Auditory Scene Analysis to represent,
match, warp, and then interpolate between two sounds. The
image on the left shows the smooth spectrogram, one of two
independent representations used when morphing audio
signals. Work we've done to morph between
two sounds is described in a paper at the 1996 ICASSP.
This work is new because it extends previous audio
morphing work to include inharmonic sounds. This paper
uses results from Auditory Scene Analysis to represent,
match, warp, and then interpolate between two sounds. The
image on the left shows the smooth spectrogram, one of two
independent representations used when morphing audio
signals. |
Web
Page
Postscript
(3M)
Adobe
PDF
(237k)Patent
|
| I wrote an article describing my experiences writing
"intelligent" signal processing documents. My Mathematica
notebook "Lyon's Cochlear Model" was the first large
document written with Mathematica. While I don't use
Mathematica as much as I used to, I still believe that
intelligent documents are a good way to publish scientific
results. These ideas were also published in a book titled
"Knowledge Based Signal Processing" that was published by
Prentice Hall. |
KBSP
Book
Chapter in Adobe PDF (3M)
IEEE
Signal
Processing Article in Adobe PDF (2M)
|
Software Publications
 I have written Matlab m-functions
that read and write QuickTime movies. The WriteQTMovie code
is more general than previous solutions for creating movies
in Matlab. It runs on any platform that Matlab runs on. It
also lets you add sound to the movie. The ReadQTMovie code
reads and parses JPEG compressed moves. I have written Matlab m-functions
that read and write QuickTime movies. The WriteQTMovie code
is more general than previous solutions for creating movies
in Matlab. It runs on any platform that Matlab runs on. It
also lets you add sound to the movie. The ReadQTMovie code
reads and parses JPEG compressed moves. |
Matlab
Source
Code |
 Chris
Bregler and I coded an implementation of an image
processing technique known as snakes. There are two m-files
that implement a type of dynamic contour following popular
in computer vision. First proposed by Kass, Witkin and
Terzopoulos in 1987, snakes are a variational technique to
find the best contour that aligns with an image. The basic
routine, snake.m, aligns a sequence of points along a
contour to the maximum of an array or image. Provide it with
an image, a set of starting points, limits on the search
space and it returns a new set of points that better align
with the image. The second m-file is a demonstration script.
Using your own array of image data, or a built-in default, a
demo window is displayed where you can click to indicate
points and see the snake program in action. Chris
Bregler and I coded an implementation of an image
processing technique known as snakes. There are two m-files
that implement a type of dynamic contour following popular
in computer vision. First proposed by Kass, Witkin and
Terzopoulos in 1987, snakes are a variational technique to
find the best contour that aligns with an image. The basic
routine, snake.m, aligns a sequence of points along a
contour to the maximum of an array or image. Provide it with
an image, a set of starting points, limits on the search
space and it returns a new set of points that better align
with the image. The second m-file is a demonstration script.
Using your own array of image data, or a built-in default, a
demo window is displayed where you can click to indicate
points and see the snake program in action. |
Matlab
Source
Code
Matlab
Demonstration
Source
|
| Michele Covell and I wrote some Matlab code
to compute multi-dimensional scaling (MDS). MDS allows you
to reconstruct an estimate of the position of points,
given just relative distance data. These routines do both
metric (where you know distances) and non-metric (where
you just now the order of distances) data. |
Technical
report
containing the code (no documentation). |
Apple Publications
| The SoundAndImage toolbox is a collection of Matlab
tools to make it easier to work with sounds and images. On
the Macintosh, tools are provided to record and playback
sounds through the sound system, and to copy images to and
from the scrapbook. For both Macintosh and Unix system,
routines are provided to read and write many common sound
formats (including AIFF). Only 68k MEX files are included.
Users on other machines will need to recompile the software.
This toolbox is published as Apple Computer Technical Report
#61. |
Postscript
Documentation
(153k)
Adobe
PDF
Documentation (20k)
Macintosh
Archive
|
 I created a Hypercard stack to make it
easier for people with a Macintosh and CDROM drive to
interact with the Acoustical Society of America's Auditory
Demonstrations
CD. This CD is a wonderful collection of auditory
effects and principles. The ASA Demo Hypercard stack
includes the text and figures from the book and lets you
browse the Audio CD. I created a Hypercard stack to make it
easier for people with a Macintosh and CDROM drive to
interact with the Acoustical Society of America's Auditory
Demonstrations
CD. This CD is a wonderful collection of auditory
effects and principles. The ASA Demo Hypercard stack
includes the text and figures from the book and lets you
browse the Audio CD. |
Macintosh
Archive |
 I wrote a program for the Macintosh 660/AV
and 840/AV computers that uses the DSP (AT&T3210) to
monitor audio levels. VUMeters runs on any Macintosh with
the AT&T DSP chip. Source and binaries are included. I wrote a program for the Macintosh 660/AV
and 840/AV computers that uses the DSP (AT&T3210) to
monitor audio levels. VUMeters runs on any Macintosh with
the AT&T DSP chip. Source and binaries are included. |
Macintosh
Archive |
 Bill Stafford and I wrote TCPPlay to allow us
to play sounds from a Unix machine over the network to the
Macintosh on our desks. This archive includes Macintosh
and Unix source code and the Macintosh application. There
are other network audio solutions, but this works well on
the Macintosh. Bill Stafford and I wrote TCPPlay to allow us
to play sounds from a Unix machine over the network to the
Macintosh on our desks. This archive includes Macintosh
and Unix source code and the Macintosh application. There
are other network audio solutions, but this works well on
the Macintosh. |
Macintosh
Archive |
Previous Publications
 In a past life, I worked on
medical imaging. A book on tomographic imaging
(cross-sectional x-ray imaging) was published by IEEE Press:
Avinash C. Kak and Malcolm Slaney, Principles of
Computerized Tomographic Imaging, (New York : IEEE
Press, c1988). The software used to generate many of the
tomographic images in this book is available. The parallel
beam reconstruction on the left was generated with the
commands In a past life, I worked on
medical imaging. A book on tomographic imaging
(cross-sectional x-ray imaging) was published by IEEE Press:
Avinash C. Kak and Malcolm Slaney, Principles of
Computerized Tomographic Imaging, (New York : IEEE
Press, c1988). The software used to generate many of the
tomographic images in this book is available. The parallel
beam reconstruction on the left was generated with the
commands
gen n=100 k=100 if=lib.d.s
filt n=100 k=100
back n=100 k=100
disn min=1.0 max=1.05
|
Tomographic
Software
(Unix TAR format)
Tomographic
Software
(Shell archive)
The book is now online. Download the PDF or
order the book from SIAM)
|
| Carl Crawford, Mani Azimi and I wrote a simple
Unix plotting package called qplot. Both two-dimensional and
3d-surface plots are supported. |
Compressed
Unix
TAR File |
| Now obsolete code to implement a DITroff
previewer under SunView is available. This program was
called suntroff and is an ancestor of the X Window
System Troff previewer. It was written while I was an
employee of Schlumberger Palo Alto Research. All files are
compressed Unix TAR files. |
Source
LaserWriter
fonts
Complete
package
|
Other Research Pointers
I organize the Stanford CCRMA Hearing Seminar.
Just about any topic related to auditory perception is considered
fair game at the seminar. An archive of seminar announcements can be
found at Stanford
(organized
as a table) or at UCSC as a
chronological listing of email announcements. Send email to hearing-seminar-request@ccrma.stanford.edu
if you would like to be added to the mailing list.
For more Information
I can be reached at
Malcolm Slaney
The best way to reach me is to send email.
This page last updated on September 3, 2012.
Malcolm Slaney (
malcolm@ieee.org)
 Auditory perception has been the core of my research
over the years, most recently understanding perception by
decoding brain waves.
Auditory perception has been the core of my research
over the years, most recently understanding perception by
decoding brain waves.
 Much of my work uses techniques from AI, machine-learning,
deep neural networks and Bayesian learning to solve interesting problems.
Much of my work uses techniques from AI, machine-learning,
deep neural networks and Bayesian learning to solve interesting problems.
 I've been working with several
talented
I've been working with several
talented  The information in most auditory
models flows exclusively bottom-up, yet there is
increasing evidence that a great deluge of information is
flowing down from the cortex. A paper I wrote for the
The information in most auditory
models flows exclusively bottom-up, yet there is
increasing evidence that a great deluge of information is
flowing down from the cortex. A paper I wrote for the 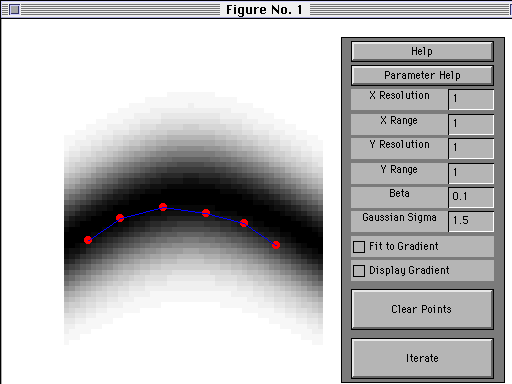
{kind=link}
{kind=link}